탄력적 검색 매핑알아 보자
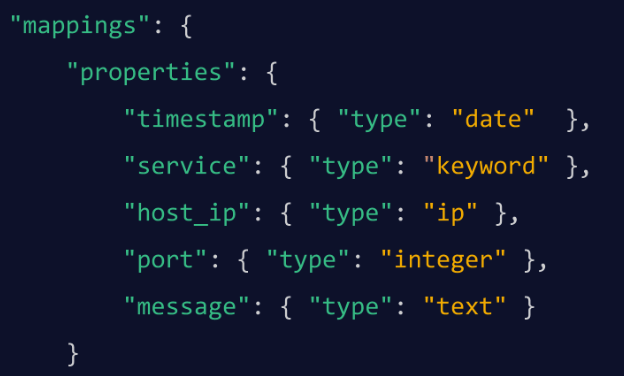
엘라스틱서치에서 매핑인덱스에 문서를 인덱싱할 때 사용 필드 및 데이터 유형정의하다. 만약 전에 매핑, 새 필드만 추가할 수 있으며 기존 필드는 수정할 수 없습니다. “index” 속성은 필드가 인덱싱되는 방식을 지정합니다. “분석“는 전체 텍스트 검색을 위한 문자열 필드를 나타냅니다. “분석되지 않음“는 정확한 값(정확한 일치)을 검색하기 위한 문자열 필드를 지정하고, “아니요“는 검색할 수 없는 필드를 정의합니다.
다양한 분야가 있습니다 단일 값 또는 다중 값(배열)오프로드도 가능 값이 비어 있거나 개체를 포함합니다.당신은 할 수 있습니다. Elasticsearch의 문서는 키-값 쌍 목록구성됩니다. 내부 개체 내의 필드는 해당 개체의 경로를 통해 액세스할 수 있습니다. (예: 사용자 이름.완성)

내부 개체에 배열이 포함되어 있으면 인덱싱에서 이러한 개체 간의 상관 관계가 손실될 수 있습니다. 이러한 연결을 유지하려면 중첩 개체내부 객체를 개별 문서로 취급합니다. 이를 통해 내부 개체 간의 상관 관계를 유지할 수 있습니다. 중첩된 개체는 별도의 문서로 저장되지만 특수 문서로 원본 문서에 종속되며 동일한 세그먼트에 저장됩니다.

우수한 데이터 검색 및 분석의 가장 중요한 부분 중 하나는 데이터 필드의 적절한 인덱싱 및 분석입니다. Elasticsearch는 다른 목적을 위해 다른 방식으로 동일한 필드를 인덱싱할 수 있습니다. 예를 들어 문자열 필드는 전체 텍스트 검색을 위한 텍스트 필드와 정렬 또는 집계를 위한 키워드 필드에 매핑될 수 있습니다.
다양한 방법으로 데이터 필드를 분석하면 검색의 정확성과 일치를 향상시킬 수 있습니다. 예를 들어, 표준 분석기로 텍스트를 단어로 분할하고 영어 분석기로 단어를 형성(첨부 파일 제거 등)할 수 있습니다.
이러한 유연성을 통해 데이터의 특성과 검색 요구 사항에 따라 적절한 인덱싱 및 분석을 수행할 수 있으며 데이터 검색 및 데이터 분석을 최적화하는 데 큰 역할을 합니다.